Clean Apex Code: SOLID Principles every senior should know
This section focuses on the SOLID principles and assumes knowledge of topics explored in previous chapters.
9.2 SOLID
SOLID stands for the following principles:
- S: Single Responsibility Principle
- O: Open/Closed Principle
- L: Liskov Substitution Principle
- I: Interface Segregation Principle
- D: Dependency Inversion Principle
The SOLID principles where popularised by Robert C. Martin, famous for his work on the Clean Code book. These are just a set of principles heavily oriented towards OOP.
9.2.1 Single Responsibility Principle
The Single Responsibility Principle (SRP) has its roots in the work of multiple computer scientists, but it was eventually coined and popularised by Robert C. Martin. The principle states that a module should only have one reason to change.
This is similar to saying that a module should not mix concerns, or that it should do one thing as we explored extensively in Chapter 3. The immediate natural question is “what is a reason?”; not to different from the “what is one thing?” question.
By now you probably now I’m a big fan of the Database class in Apex. Consider if this class has a single responsibility, or whether it does one thing, or whether it has a single reason to change? I can think of multiple reasons why this class (internally and externally) could change:
- Salesforce introduces or updates the governor limits
- Salesforce introduces new
sharingswitches for each operation type - Salesforce adds Data Cloud objects support in this class
- New capabilities that we can’t even think of emerge in years to come
So, does that mean that the Database class does follow the SPR? Not really.
According to Martin’s later works, this principle is about people and business users who benefit from our software. Let’s see an example of this.
Imagine I have a class that encapsulates all business logic related to the Case object. If you are using the fflib library (a.k.a as Apex Enterprise Patterns), you may be following a pattern like this (this is pseudo-code)
public with sharing class Cases extends ApplicationSObjectDomain{
public void getSupportCaseSLA();
public void getCaseAge();
public void createMarketingCase();
}
This looks like a reasonable class. All the logic related to dealing with Cases is nicely tied together. However, notice that the 3 methods may serve different business users.
getSupportCaseSLA:- Likely used indirectly by support agents to determine when a case response is due.
getCaseAge:- Used to create a custom report in a custom object to support quarterly business reviews conducted by Support Managers.
createMarketingCase:- Used within a Marketing application to enable the marketing team to request feature updates and documentation from the Product team.
Now, what do you think would happen if the marketing team asks for changes in this logic, and you inadvertently break how SLAs are calculated? The support team will naturally be upset that something broke due to a change they didn’t even ask for.
So, the SRP states that a responsibility or a reason to change is a group of users that have whom the module responds to. If changes to the marketing case logic can affect the SLA logic, it’s better to separate these modules so that they are only responsible for one group of users. Finally, Martin also said that another way to think of the SRP is as follows:
Gather together the things that change for the same reasons. Separate those things that change for different reasons.
This sentence is so profound that the entire next chapter is dedicated to it, so I will leave it here as a teaser for the time being.
I started by posing the question on whether the Database class does not follow the SRP? I’d argue that it follows it because the only reason for it to change is to change how Salesforce developers interact with the database. Given that we are a distinct group of people, this class follows the SPR.
To put this principle in practice, you should consider whether a module is serving different business units or completely different contexts. If this is true and if this module is likely to change constantly, you should think deeply about separating them.
9.2.2 The Open/Closed Principle
The Open/Closed Principle (OCP) states that a module should be open for extension, but closed for modification. What this means is we should be able to extend the functionality of a module without modifying the existing code; instead, we write new code.
The idea here is that if we can add behaviour to a module without modifying its core logic, less bugs are likely to occur on clients that depend on that core logic. Our classic example of the DML wrapper class is an example of the OCP.
public void execute() {
DMLExecutable operation = this.operationsByDmlAction.get(this.operation);
operation.execute(this.records, this.allowPartialSuccess);
}
We can add more DML operations simply by adding a new implementation of the DMLExecutable class. The execute method can be extended to support new logic without it being modified at all. So in a way, polymorphism is a manifestation of the OCP. In this particular example, this was an implementation of the Strategy Pattern.
We also saw in the previous chapters how we can add new behaviours of the shouldRunAgain method for all Queuable classes using the Template Method pattern.
public abstract class AutoQueueable implements Queueable{
public void execute(QueueableContext context) {
doExecute(context);
if(limitNotHit() && shouldRunAgain()){
System.enqueueJob(this);
}
}
public abstract void doExecute(QueueableContext context);
public abstract Boolean shouldRunAgain();
public Boolean limitNotHit(){
Integer queuedJobsThisTransaction = Limits.getQueueableJobs();
Integer maxQueueableJobs = Limits.getLimitQueueableJobs();
return queuedJobsThisTransaction < maxQueueableJobs;
}
}
Every time we want to add a new variation of what determines if a Queueable class should run again, we simply create a new class that implements AutoQueueable. In other words, the behaviour of AutoQueueable is open for extension without needing changes in its code (it’s closed for modification).
Another example if the Trigger Actions Framework open-source library by Mitch Spano. To add new behaviour to a trigger handler, you simply create a new class and add it to the custom metadata type that the handler reads to determine what actions should be executed
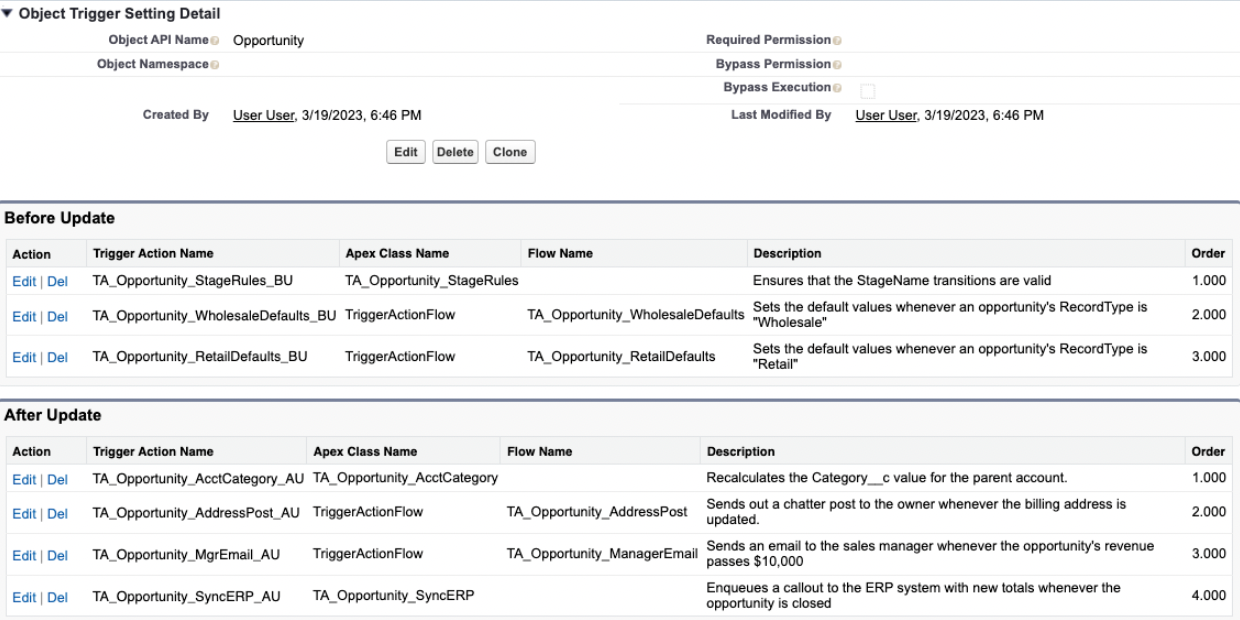
The handler class never changes. In the GitHub repo itself, Spano mentions how this frameworks follows the OCP and the SRP:
The Trigger Actions Framework conforms strongly to the Open–closed principle and the Single-responsibility principle. To add or modify trigger logic in our Salesforce org, we won't need to keep modifying the body of a TriggerHandler class; we can create a class or a flow with responsibility scoped to the automation we are trying to build and configure these actions to run in a specified order within a given trigger context.
The work is performed in the MetadataTriggerHandler class which implements the Strategy Pattern by fetching all Trigger Action metadata that is configured in the org for the given trigger context.
Now, we should only follow this principle when we know (either by evidence or experience in the domain) that the behaviour is very likely to change or have variations. For example, if Salesforce only supported 2 DML operations for the past 10 years, the following method would be completely acceptable:
public void execute() {
switch on this.operation {
when INSERTS {
executeInsert(this.records, this.allowPartialSuccess);
}
when UPDATES {
executeUpdate(this.records, this.allowPartialSuccess);
}
I would be wasteful to use the strategy pattern just to hide such simple boolean logic. However, we know there are multiple DML operations and we know Salesforce has added new variations in recent years (with sharing, async, etc), so in this case, it makes sense for the execute method to allow extension without modification.
9.2.3 The Liskov Substitution Principle
The Liskov Substitution Principle (LSP) was created by Barbara Liskov in 1988. The principle states that subtypes must be substitutable for their base types. Another way of saying this is that a program that uses an interface or base type must not be confused by a specific implementation.
Consider this example. As you know by now, the Database methods (insert, update, etc.) act on the SObject type and not the specific type, and so the following works
Contact record = [SELECT Id FROM Contact LIMIT 1];
Database.update(record, true);
The update method would behave the same way if record was an Opportunity
Opportunity record = [SELECT Id FROM Opportunity LIMIT 1];
Database.update(record, true);
As we’ve seen already, this works because all specific object types inherit from the SObject class. So far, this logic follows the LSP. You can use a specific type of record anywhere where an SObject type is expected.
However, the logic breaks when you pass a converted lead
Lead record = [SELECT LastName FROM Lead WHERE IsConverted = TRUE LIMIT 1];
Database.update(record, true);
This fails with the following error
CANNOT_UPDATE_CONVERTED_LEAD, cannot reference converted lead: []
The issue here is that converted leads cannot be updated. This restriction is specific to Lead records, diverging from the general behavior of SObject. To handle this, you are forced to introduce type-specific logic:
if (record instanceof Lead) {
Boolean isConverted = [SELECT IsConverted FROM Lead
WHERE Id = :record.Id].IsConverted;
if(isConverted){
//do nothing, cannot update
}
else{
Database.update(record, true);
}
}
else{
Database.update(record, true);
}
Checking for the specific type of a type (i.e record instanceof Lead) is known as “type-narrowing”. You are trying to narrow down the specific type because you know that it does not conform to the contract specified in the base class (SObject in this case).
This diverges from the LSP because you should be able to use Lead every time you have a reference to an SObject, but it turns you, you can’t when it comes to DML updates. What was a clean and short method, is now polluted with logic specific to a particular type. This also diverges from the Open/Closed Principle because if there are more types that need special handling, the method needs to be updated every time we find such special case. In other words, it’s not closed for modification.
In this particular case, it’s the Lead class who diverges from the principle.
To summarise: If a subclass needs special behavior that breaks the parent class’s contract, you might want to reconsider whether:
- Inheritance is the correct design choice.
- The parent class’s design needs to be rethought.
9.2.4 The Interface Segregation Principle
The Interface Segregation Principle (ISP) states we should keep interfaces small and specific so that modules don’t depend on things they don’t need.
Basically this means that interfaces should enforce one thing. We already know from the previous chapter that interfaces are used to force classes to adhere to a contract so that we can create polymorphic methods that can act on the interface and not the specific implementations. The ISP encourages us to keep our contracts small and to not force classes to implement behaviour they don’t need.
A good example of this is batch Apex. To create a batch class, you have to implement the Database.Batchable interface, like this
public class SummarizeAccountTotal implements
Database.Batchable<sObject> {
...
However, batch Apex also offers two additional, optional interfaces:
Database.RaisesPlatformEvents: Allows the class to fire platform events.Database.Stateful: Allows the class to maintain state across transactions.
public class SummarizeAccountTotal
implements Database.Batchable<sObject>,
**Database.RaisesPlatformEvents,
Database.Stateful** {
...
Salesforce split these behaviours into separate interfaces because not all batch classes need to raise platform events or remember the state of previous transactions. If these 2 behaviours were baked into the Database.Batchable class, our classes would likely need some logic to bypass that behaviour or to make exceptions. Those exceptions would contradict the LSP as we saw in the previous section.
In short, the ISP encourages us to keep our interfaces focused, specific and where possible optional.
9.2.5 The Dependency Inversion Principle
The Dependency Inversion Principle (DIP) is probably the most misunderstood of the SOLID principles, and it’s also the hardest to explain. Let me start by saying that the DIP is not the same as Dependency Injection (DI). I will explain DI in detail later.
The understand this principle, we must understand two concepts first. Classes or modules can be divided in 2 categories:
- Policy: A class or module defines a high-level policy or business requirement.
- Detail: A lower level module defines the details that support the policy.
Let’s imagine that I have a very complex Lead conversion process. The high level policy or requirement is in the CustomLeadConversion class (this is pseudo code):
public class CustomLeadConversion {
public void convertLead(Lead lead);
public void convertLeads(List<Lead> leads);
public List<Lead> getConvertedLeads();
public Boolean isEligibleForConversion(Lead lead);
}
Now, imagine this class became so complex, that you decided to place lower level methods into a separate class, called LeadConversionUtils (we already spoke about whether utility classes are an anti-pattern or not). This class deals with the details that are not so important from a business point of view, such as querying the database, logging error messages, etc.
public class LeadConversionUtil {
public List<String> getFieldsToMap();
public Boolean isFieldMappable(String fieldName);
public Boolean isFieldMappable(Schema.SObjectField field);
public List<Lead_Conversion_Field_Mapping__mdt> getLeadConversionFieldMappings();
}
With this new class in place, CustomLeadConversion will make calls to LeadConversionUtil in different places.
public class CustomLeadConversion {
//the policy uses the detail for lower level operations
//we'll make this better with dependency injection in a bit
**private LeadConversionUtil utils = new LeadConversionUtil();**
public void convertLead(Lead lead);
public void convertLeads(List<Lead> leads);
public List<Lead> getConvertedLeads();
public Boolean isEligibleForConversion(Lead lead);
}
The DIP states that at this point, the high level policy depends on the details. If we make changes to LeadConversionUtil , the policy will be impacted. Such dependency is undesirable. The detail exists to serve the policy, so it makes sense for the detail to depend on the policy's requirements, not the other way around.
Imagine for a moment that I impersonate the policy class CustomLeadConversion. Here’s what my thought process would be:
To satisfy this complex lead conversion process, I need to interact with the database, get custom settings, etc. Currently, I depend on you, LeadConversionUtil . I don’t like that. I’m the policy. Why should you define what operations I can call on you?
I should be the one to tell you what I need! So, I’m going to give you a contract that defines what operations I need and you will implement it. I’m not too interested in how you do that as long as you satisfy my contract. If I ever some new functionality, I’ll amend the contract and let you know.
To satisfy the DIP, CustomLeadConversion must define a contract that defines what lower level operations it needs, and then both classes will depend on that contract. Here’s what it would look like:
public class CustomLeadConversion {
public **interface** **ILeadConversionUtil** {
public List<String> getFieldsToMap();
public Boolean isFieldMappable(String fieldName);
public Boolean isFieldMappable(Schema.SObjectField field);
public List<Lead_Conversion_Field_Mapping__mdt> getLeadConversionFieldMappings();
}
**private ILeadConversionUtil utils;**
public void convertLead(Lead lead);
public void convertLeads(List<Lead> leads);
public List<Lead> getConvertedLeads();
public Boolean isEligibleForConversion(Lead lead);
}
Now, CustomLeadConversion has defined what it needs through the ILeadConversionUtil interface. Notice that the reference to utils has changed to the interface too.
Now, we just have to make LeadConversionUtil implement ILeadConversionUtil. I will also rename it to LeadConversionUtilImpl so that it’s clear which is which
I and to suffix their implementations with the word Impl.public class LeadConversionUtilImpl implements CustomLeadConversion.ILeadConversionUtil {
...
}
With this design, CustomLeadConversion no longer depends on LeadConversionUtilImpl from a purely technical point of view. CustomLeadConversion doesn’t have a reference to LeadConversionUtilImpl anywhere. It only has a reference to its interface ILeadConversionUtil.
From a philosophical point of view, it’s now CustomLeadConversion who determines what the detail should be. The detail class now must implement the interface defined by the policy. The detail depends on what the policy defines in the contract, which means the dependency has been inverted.
I recommend reading the above a few times before you continue.
Now, I argue that on its own, the DIP achieves nothing. All we’ve done here is added an additional module that creates an artificial separation between the policy and the detail. Even if the policy defines what the detail should do, the detail class still defines how it actually does it, and that can still break the policy. So the idea that the policy no longer depends on the detail is somewhat artificial.
However, the DIP is powerful when you couple it with Dependency Injection (DI), and both of them combined are the entire foundation for advanced mocking and testing. DI is a large topic, so for now, I will provide a naive explanation just so that we can understand how the DIP is useful.
Dependency Injection is simply 2 things:
- Pass dependencies via a constructor
- Hide those dependencies behind an interface
In our example, we can now modify the constructor of CustomLeadConversion to take an implementation of ILeadConversionUtil, like this
public class CustomLeadConversion {
public CustomLeadConversion(ILeadConversionUtil leadConversionUtil) {
this.leadConversionUtil = leadConversionUtil;
}
Now, CustomLeadConversion really doesn’t know about the specific implementation (LeadConverstionUtilImpl). This class will be passed to it via the constructor and thanks to polymorphism, we can refer to it with its base type.
That’s really dependency injection. With this in place, you can do very interesting things. For example, when testing, you can pass a mock implementation of ILeadConverstionUtil, for example
public class LeadConversionUtilMock implements ILeadConversionUtil{
//mock implementation of all the methods
}
And then
@IsTest
public static void testConvertLead(){
//define the variable as the base type
//but instantiate the mock implementation (polymorphism!!)
CustomLeadConversion.ILeadConversionUtil leadConversionUtil = new CustomLeadConversion.LeadConversionUtilMock();
//pass the mock implementation to the constructor
CustomLeadConversion customLeadConversion = new CustomLeadConversion(leadConversionUtil);
}
Now, CustomLeadConversion has been instantiated with a fake implementation of the detail class. That means that now, we can focus on testing CustomLeadConversion assuming that the detail does what it needs to do. This helps us make our tests more focused on a specific behaviour we want to test, without relying on the dependencies of that behaviour. If this isn’t clear, don’t worry, I’ll spend a lot more time on this in the last chapter.
And so, here’s where the DIP really comes in. If we want to hide dependencies behind an interface, do we model the interface as a mirror of the methods in the dependency, or do we model it based on the caller’s needs?
In other words, rather than creating a generic Lead utility class and create an interface that defines the methods on the class, we define the interface based on the needs of the high level policies. That’s what the DIP is all about.
Let’s try to summarise this section:
- The Dependency Inversion Principle states that high-level policies should define the rules, while low-level details follow them.
- When combined with Dependency Injection, DIP becomes a foundation of decoupled architecture and testable modules.
- In practice, always consider the needs of the high-level policies when designing abstractions. Resist the temptation to let the implementation details drive the design; it's the policies that should dictate the dependencies.
- Bonus: Be careful not to overuse the DIP. There is still value in generic modules that satisfy multiple clients via utility methods. Forcing every utility to serve a specific client reduces our chances of reusing that utility.