Clean Apex Code: Cascading Failures in Trigger Boundaries
In the previous chapter, we discussed several techniques for validating parameters and variables. The whole reason for doing these type of validations is to prevent errors or exceptions in our code. There are some types of errors and exceptions that are much harder to reason about, specially because they require a deep understanding of Apex’s transaction model. In this chapter, we explore how to prevent cascading failures in Apex triggers.
7.1 The exception dilemma
All the code you’ve seen so far in this book omits exception handling. This is on purpose because as we’ll see shortly, how and where you handle exceptions is a complex topic that deserves a whole chapter.
To illustrate the complexity that exceptions bring to an Apex codebase, consider the scenario where over a period of 1 year, the business requested to implement the following 3 requirements.
- When an account owner is changed, the opportunities are reassigned to the new owner
- When an opportunity is assigned to a user, a task is created for them.
- When a task is created, we increase the open task count field on the owner’s user record
Consider as well, that not all requirements were requested at the same time, and each of them was implemented by a different developer.
Here’s how each requirement is implemented at a high level:
Account owner change > reassign opportunities
Trigger.AccountTrigger
Class.AccountTriggerHandler.afterUpdate
Class.AccountTriggerHandler.onOwnerChange
Class.AccountOwnership.reassignRelatedRecords
Class.AccountOwnership.reassignOpptys (executes a DML on Opportunity)
Opportunity assigned > create task
Trigger.OpportunityTrigger
Class.OpportunityTriggerHandler.afterUpdate
Class.OpportunityTriggerHandler.notifyNewOwners (executes a DML on Task)
Task created > increment task count
Trigger.TaskTrigger
Class.TaskTriggerHandler.afterInsert
Class.TaskTriggerHandler.increaseOpenTaskCount (executes a DML on User)
You may have noticed that even though each requirement is independent, they will all run in sequence when the first one is triggered. For example, if an account’s owner is updated:
- The opportunities will be reassigned to the new owner
- This triggers the creation of a task for the new owner, and
- This triggers the update on the user record to reflect the count of open tasks
In other words, when an account owner’s is updated, the path of the code is as follows (in this order):
Trigger.AccountTrigger
Class.AccountTriggerHandler.afterUpdate
Class.AccountTriggerHandler.onOwnerChange
Class.AccountOwnership.reassignRelatedRecords
Class.AccountOwnership.reassignOpptys (executes a DML on Opportunity)
Trigger.OpportunityTrigger
Class.OpportunityTriggerHandler.afterUpdate
Class.OpportunityTriggerHandler.notifyNewOwners (executes a DML on Task)
Trigger.TaskTrigger
Class.TaskTriggerHandler.afterInsert
Class.TaskTriggerHandler.increaseOpenTaskCount (executes a DML on User)
Now, let’s say that the business wants to make sure that each user has a fair work load and so the number of open tasks assigned to one user should not exceed 4 open tasks. This requirement was then implemented as a simple validation rule on the user object. With this validation rule in place, the last action on this stack trace can throw a DML exception, like this
Trigger.AccountTrigger
Class.AccountTriggerHandler.afterUpdate
Class.AccountTriggerHandler.onOwnerChange
Class.AccountOwnership.reassignRelatedRecords
Class.AccountOwnership.reassignOpptys (executes a DML on Opportunity)
Trigger.OpportunityTrigger
Class.OpportunityTriggerHandler.afterUpdate
Class.OpportunityTriggerHandler.notifyNewOwners (executes a DML on Task)
Trigger.TaskTrigger
Class.TaskTriggerHandler.afterInsert
Class.TaskTriggerHandler.increaseOpenTaskCount (executes a DML on User)
**System.DmlException: Update failed. FIELD_CUSTOM_VALIDATION_EXCEPTION**
You have too many open tasks!
If we don’t have any exception handling anywhere, the exception will bubble up all the way to the Trigger.AccountTrigger execution. For example, if I add a simple try/catch block on the code that changes the account owner, we can see that the DML exception on the user object arrives all the way here:
try{
account.OwnerId = newOwnerId;
update account;//this will fire Trigger.AccountTrigger
} catch (Exception e){
// **System.DmlException: Update failed. FIELD_CUSTOM_VALIDATION_EXCEPTION**
// You have too many open tasks!
}
This is standard behavior in Apex: exceptions propagate up the call stack, traveling through each layer of execution until they are caught by a try/catch block.
And here’s where things get complicated. An exception 4 levels deep from a different business process has bubbled up to the account trigger, which fired for unrelated reasons. Here, I encourage you to pause and ponder the following questions:
- Who should have caught this exception?
- Should it have been caught at the source (
TaskTriggerHandler.increaseOpenTaskCount) , somewhere in the middle, or by the parent process (Trigger.AccountTrigger)? - Which code has the necessary context and knowledge to understand what to do with this exception and how to recover from it?
- How does Apex distinguish where one business process ends and another begins?
Let’s address some of these questions while keeping this scenario in mind.
7.2 Business process boundaries and atomic operations
In the example above, Apex is executing 3 different business processes in the same transaction due to how triggers work. But how do we determine if all 3 business processes combined are meant to be considered a single atomic operation? An operation is atomic when every step must succeed, or none should. This is important when we don’t want partial updates that leave the system in an inconsistent state.
To illustrate this, let’s pivot to a simpler example. Here, I’ve created a validation rule that will make any task insert to fail. Here’s an example of a non-atomic operation:
try {
insert new Account(Name='Non Atomic Account');
insert new Contact(LastName='Non Atomic Contact');
//This will fail due to a validation rule
insert new Task(Subject='Non Atomic Task', ActivityDate=Date.today());
}
catch(Exception e){
Account a = [SELECT Id FROM Account WHERE Name = 'Non Atomic Account'];
Contact c = [SELECT Id FROM Contact WHERE LastName = 'Non Atomic Contact'];
Assert.istrue(a != null);
Assert.istrue(c != null);
}
In this example, the account and contact are inserted successfully, even though an error is thrown when inserting the task. Interestingly, the first 2 inserts succeed only because we are catching the exception. If we don’t catch the exception, the entire operation is rolled back, for example
public static void defaultBehaviour(){
insert new Account(Name='Default Account');
insert new Contact(LastName='Default Contact');
//This will fail due to a validation rule
insert new Task(Subject='Atomic Task', ActivityDate=Date.today());
}
In the above example, the account and contact are not committed to the database; everything is rolled back. This is expected behaviour as far as Apex is concerned, but it might not be what you expect.
If the set of operations is meant to be atomic, we can explicitly ensure that no partial updates are made by using a database save point. This means that if any step fails, everything is rolled back, preventing partial success that could leave the system in an inconsistent state.
Savepoint sp = Database.setSavepoint();
try{
insert new Account(Name='Test Account');
insert new Contact(LastName='Test Contact');
insert new Task(Subject='Test Task', ActivityDate=Date.today());
}
catch(Exception e){
Database.rollback(sp);
}
In the above example, when the exception is caught, we rollback the database to the point just before the first DML operation. This effectively means that if any error occurs on any of the DML calls, all 3 are rolled back. All 3 steps act as a single unit of work.
How is this related to the example explored in section 7.1? We need to determine if the 3 steps are meant to be atomic or not. In pseudo-code:
User updates account owner
1. Account trigger reassigns opportunities
2. Opportunity trigger creates tasks
3. Task trigger updates count on user record
Are all these 3 part of a single business process? How do we tell? When I introduced this example, I mentioned that the 3 requirements were requested separately over a period of 1 year, and that each requirement was implemented by different developers. We can then assume that when requirement 2 was requested, the business wasn’t thinking it as an extension of requirement 1. However, this is only an assumption, we really can’t tell.
We could try asking the business but they are unlikely to even know all 3 steps exist. Perhaps one business unit requested steps 1 and 2, and another one requested step 3. The reality is that unless you were there when all 3 requirements were requested, and you yourself implemented them, it’s nearly impossible to tell if they are meant to act as an atomic operation.
How can we ensure others know if our code is meant to be atomic?
7.3 Avoid using triggers for cross-object operations
One way to avoid the atomic vs non-atomic dilemma we explored in section 7.2 is to avoid using triggers for business processes that span multiple objects. Let’s assume that the example in 7.1 (the 3 main requirements we’ve been working with so far) was meant to be a single atomic operation. In that case, I argue that all the DML operations and the business logic should have been part of the a single deep module (see chapter 4).
For example, we could do something like this in the AccountOwnership class
public static void reassignRelatedRecords(Map<Id,Id> ownerIdsByAccountId){
Database.Savepoint sp = Database.setSavepoint();
try{
reassignOpptys(ownerIdsByAccountId);
createTasksForNewOwners(ownerIdsByAccountId);
increaseOpenTaskCount(ownerIdsByAccountId);
}
catch(Exception e){
ExceptionLogger.log(e,'AccountOwnership.reassignRelatedRecords');
Database.rollback(sp);
}
}
First, all the functionality related to account reassignment is inside the reassignRelatedRecords method. This makes it a deep module; it does everything it needs to do and provides a simple interface. Second, we wrap everything inside a database save point, allows us to handle failures gracefully while leaving the database in a consistent state. Finally, when other developers see this code, it will be immediately obvious that all these 3 operations combined are meant to be atomic. This is better than spreading out the business requirement across different triggers, as it’s nearly impossible to tell if one trigger is meant to be the continuation of another process somewhere else.
Furthermore, if you split a single business process across multiple triggers, this means that by design, the operation isn’t atomic. In our example, the opportunity trigger could fire whether or not the account owner was changed, or the task trigger could fire even if the account doesn’t have opportunities. In other words, each step of the process can start independently, which means all 3 steps are not a unit of work. The best thing to do is to not use multiple triggers to design an atomic process that spans multiple objects. Instead, consolidate the logic in a deep module where you have full control on the atomicity of the operation.
7.4 Apex transactions are atomic by default
As we saw earlier, Apex transactions are atomic by default. Consider the simpler example we saw above
public static void defaultBehaviour(){
insert new Account(Name='Default Account');
insert new Contact(LastName='Default Contact');
//This will fail due to a validation rule
insert new Task(Subject='Atomic Task', ActivityDate=Date.today());
}
Because we aren’t catching any exceptions, any exception will cause all DML operations to be rolled back, which means the operation is atomic by default. This is just a simplified version of our main example. In section 7.2, I showed how the exception 4 levels deep bubbled up to the parent process
try{
account.OwnerId = newOwnerId;
update account;//this will fire Trigger.AccountTrigger
} catch (Exception e){
// **System.DmlException: Update failed. FIELD_CUSTOM_VALIDATION_EXCEPTION**
// You have too many open tasks!
}
This means that if I hadn’t caught the exception, the account ownership change would have been rolled back, along with all the other DML operations in the call stack. I call this a cascading failure.
So, while the business may not have intended for these 3 operations to be consolidated into one unit of work, the default behaviour of Apex exceptions make them behave as 1. This brings some interesting questions:
- What if you don’t want these 3 operations to act as 1?
- What if you wanted to allow for exceptions in the task trigger handler while still allowing the account ownership to succeed?
- How should you model your Apex code to accomplish this?
7.5 Decoupling in trigger frameworks
Traditional literature on trigger frameworks covers about 2 types of decoupling:
- Deployment-time decoupling: This is about decoupling the trigger handlers from the trigger themselves so that they don’t reference each other directly. Most trigger frameworks achieve this by using custom metadata types and dynamically instantiating handler Apex classes.
- Governor-limit decoupling: This is about spinning of a separate asynchronous transaction or thread to enjoy higher governor limits that are independent of the original thread.
We are missing 2 types of decoupling: decoupling triggers so that failures in one trigger don’t cause a cascading failure and decoupling triggers to avoid mixing different business processes in the same thread. In many cases, these 2 are just 2 sides of the same coin.
There are 2 ways to achieve this level of decoupling:
- Use some form of asynchronous process
- Triggers should not let exceptions bubble up, unless certain conditions are met
Let’s explore these patterns.
7.5 Async processing to avoid cascading failures
As we saw earlier, an exception in a trigger handler that is several levels deep in the stack can cause all preceding processes to fail. To avoid this, our goal is to allow a sub-process to fail without impacting the parent process.
A good example of when to decouple sub-processes is in after triggers. By definition, after triggers are used primary to fire sub-processes on records other than the record that caused the trigger to fire. Here’s where you should think if such processes are really part of the same business process or if they are simply coupled together because of how Apex works. In the context of cascading failures, we should consider whether DML failures on related records that occur in an after trigger should cause the original process to fail as well.
Let’s assume you determine that the after logic should be decoupled as its a completely different business process. How can asynchronous processing help us achieve this decoupling?
7.5.1 Using Queueable Apex to isolate failures
One possible way is to use Queueable apex. You could wrap all after operations in a class that implements the Queueable interface, like this
switch on Trigger.operationType {
when BEFORE_INSERT {
//call some classes
}
when AFTER_INSERT, AFTER_UPDATE {
// this is a custom type
TriggerEvent event = new TriggerEvent()
.setNewRecords(Trigger.newMap)
.setOldRecords(Trigger.oldMap)
.setOperationType(Trigger.operationType);
**System.enqueueJob(new TaskAfterTriggerHandler(event));**
}
}
In this example, all the after logic is encapsulated in the TaskAfterTriggerHandler class. The class takes a TriggerEvent class, which is simply a wrapper for the Trigger context variables. This lets the handler work with the trigger context even if the operation happens in a different thread. Going back to our goal, the benefit is that any failures that occur in this class will not affect the before trigger handlers, so creating or updating a task will succeed no matter what happens in the after handler. Assuming that the after handler has a lot of side-effects on other objects as part of different business processes, we’ve effectively avoided cascading failures.
Now, there are some serious drawbacks to this approach. A few come to mind:
By definition, the async handler will run on a separate thread and only when resources are available (there’s no SLA for async processing). Because of this, the handler could try to execute some logic that is no longer valid because the original records have changed since the async process was queued. You could solve this by re-querying the context records in the handler and evaluate if the original criteria is still met.
Another problem is there are serious limits to how many Queueable processes you can spin off, specially if you are already in an async context (see the Apex documentation for specific details). You could quickly max out your daily allocation of Queueable apex, which is arguably worse than cascading failures, specially considering you can’t try/catch governor limit exceptions.
Finally, it’s great that we’ve isolated failures from the parent process, but if failures do occur, how do we get notified and how do we debug them? In order for this pattern to work well, you must use a good logging framework such as Nebula Logger or Pharos Triton, and you must have a process to review errors and exceptions.
Let’s explore another alternative.
7.5.2 Using Change Data Capture to isolate failures
Change Data Capture (CDC) is a feature that fires a specific type of platform event in response to changes in Salesforce records. The official use case for it is to sync Salesforce data with external systems in near-real time. However, buried somewhere deep in in the documentation, we can find the following statement:
With Apex triggers, you can capture and process change events on the Lightning Platform. Change event triggers run asynchronously after the database transaction is completed. Perform resource-intensive business logic asynchronously in the change event trigger, and implement transaction-based logic in the Apex object trigger. By decoupling the processing of changes, change event triggers can help reduce transaction processing time.
I find it interesting that the documentation itself mentions decoupling as a benefit of using CDC. However, it only mentions decoupling in the context of processing time, not business process or failure decoupling. That doesn’t mean it cannot be used for that purpose. Let’s see how.
Having configured CDC, you can create a trigger that catches updates on an object. Here’s what such a trigger would look like for the Account object
recordIds variable.trigger ChangeEventAccountTrigger on AccountChangeEvent (after insert) {
for (AccountChangeEvent event : Trigger.New) {
EventBus.ChangeEventHeader header = event.ChangeEventHeader;
if (header.changeType == 'UPDATE') {
List<String> accountIds = header.recordIds;
List<Account> accounts = [SELECT Id, Industry FROM
Account WHERE Id IN :accountIds];
for (String field : header.changedFields) {
if (field == 'Industry') {
for (Account acc : accounts) {
// do something
}
}
}
}
}
}
Here, we respond to a change in the account object and we can determine what fields have changed via the changedFields variable, just like we can do in a trigger. From here on, we can execute other logic that should be independent of the original parent process (whichever process changed an account record).
Again, going back to our goal, any failures that occur here will not affect the parent process, which is good if those failures are on a completely different logical business process. However, like in the case of Queueable, there are several drawbacks. The first one is you need licenses to enable CDC in more than 5 objects, which makes this pattern very expensive to implement.
Also, unlike with Queuable, the CDC trigger runs under the Automated Process user, which means capturing debug logs via the developer console is not possible. You have to configure specific debug logs for this special user. Finally, we also need very strong logging mechanisms to be able to react to any failures that occur here.
Still, even with these drawbacks, the core idea here is that in certain scenarios you could use CDC to isolate business processes that would otherwise run in the same thread. Isolating those processes prevents cascading failures, which simplifies exception handling.
7.5.3 Using Platform Events to isolate failures
Platform Events can be used to isolate failures by triggering events in response to specific actions, allowing the subsequent processing to run asynchronously in a separate thread through a Platform Event trigger.
For example, suppose you create a platform event New sObject that is meant to fire every time new records are created. For example
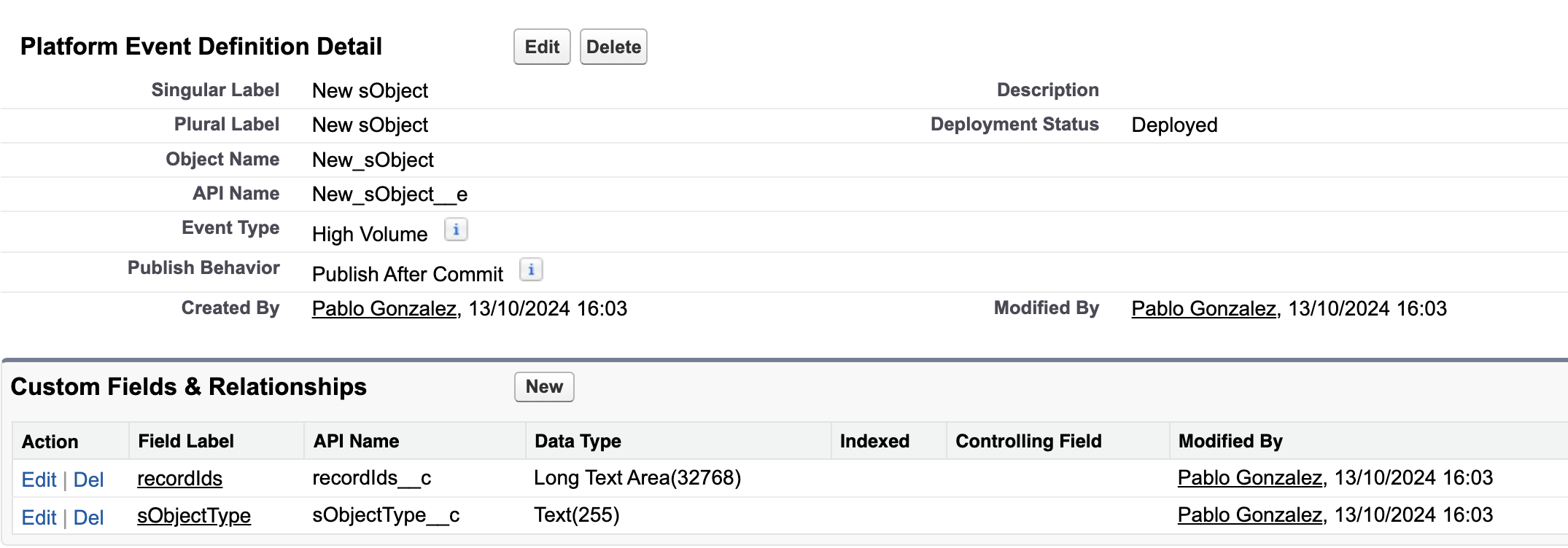
This is a generic platform event that notifies subscribers when new records are created. The recordIds__c field allows us to include all new record IDs, so we only need to fire one event per bulk transaction. Another approach is to flag the new records with a field like processing_required__c, which the platform event trigger would then query.
Both patterns are simply ways to signal changes in data, and which one you use is somewhat irrelevant to our discussion on decoupling business processes.
The sObjectType__c field can then be used to determine what type of object this is. With this configuration, you can fire an event every time new records are created, like this
String taskIds = '';
for(Task t : newTasks){
taskIds += t.Id + ',';
}
taskIds = taskIds.removeEnd(',');
New_SObject__e event = new New_SObject__e(
recordIds__c = taskIds,
SObjectType__c = 'Task'
);
Database.SaveResult result = EventBus.publish(event);
Then, you can write a trigger on the New_SObject__e platform event that will catch the event and execute some business logic. Again, the idea is that this business logic is separate from the original logic that created the task records, thus preventing cascading failures.
Such a trigger could look something like this
trigger NewSObjectTrigger on New_SObject__e (after insert) {
for (New_SObject__e event : Trigger.New) {
Set<Id> recordIds = new Set<Id>();
for (String recordId : event.recordIds__c.split(',')) {
recordIds.add(recordId);
}
switch on event.SObjectType__c {
when 'Task' {
Map<Id,Task> newTasksById = new Map<Id,Task>([
SELECT Id, OwnerId, CompletedDateTime, Subject
FROM Task
WHERE Id IN :recordIds]);
TaskCounter.increaseOpenTaskCount(newTasksById);
}
}
}
}
Like the previous two alternatives, this one also has its drawbacks. The logic runs under the Automated Process user, which can make debugging complicated.
One concern with both platform events and CDC is that ironically, the process and its subprocesses can become too decoupled. Your main process creates some records and optionally fires an event, and that's it; there’s no clear indication of what happens next. It may not be obvious to other developers that other business processes will fire in response to those events.
All in all, it’s clear that no pattern is perfect. As I mentioned at the start of this section, these are intended as thinking patterns, not “ready-to-go” implementations. When considering exception handling, we should first determine whether we are dealing with an exception that’s part of the main process or one that’s entirely unrelated. If it’s the latter, we should then ask whether the subprocess can or should run on a separate thread. In many cases, this can simplify exception handling by allowing us to focus on managing direct exceptions rather than unrelated ones.
7.6 Triggers should be able stop all exceptions
In the previous section, we explored how asynchronous processing can help prevent cascading failures. However, each method comes with its own drawbacks that, depending on the situation, can create new challenges. In this section, we'll explore alternative ways to prevent cascading failures without relying on async processing.
One of the reasons I excluded exception handling from all the examples in this book up until now, is because what you actually do with an exception depends on the context. Let’s revisit the example we used in the preceding sections. We have a task trigger that increases a counter on the user record each time a task is created
public static void afterInsert(Map<Id, Task> newTasksById){
increaseOpenTaskCount(newTasksById);
}
If this method is called 4 levels deep in a transaction, as we saw earlier, any exceptions that occur here can bubble up all the way to the parent process, reverting all DML operations along the way. And so, let’s say that we want to add exception handling logic to this bit of code by adding a try/catch block, like this
try {
increaseOpenTaskCount(newTasksById);
} catch (Exception e) {
// TBD
}
Now, what should happen if an exception happens here? If an exception occurs when this method is 4 levels deep in the stack, we could argue that we don’t want to let it bubble up all the way to the parent process. So we could do something like this
try {
increaseOpenTaskCount(newTasksById);
} catch (Exception e) {
//log it to a custom object so it doesn't
//disrupt all the processes before it
Logger.error(e.getMessage());
Logger.saveLog();
}
However, what if the exception happens when increaseOpenTaskCount is the first method on the stack? What if the user manually created a task? In that case, I argue that we should let the exception bubble up to the parent process, which is the Salesforce UI. This way, the user would see the exception in the Salesforce UI itself
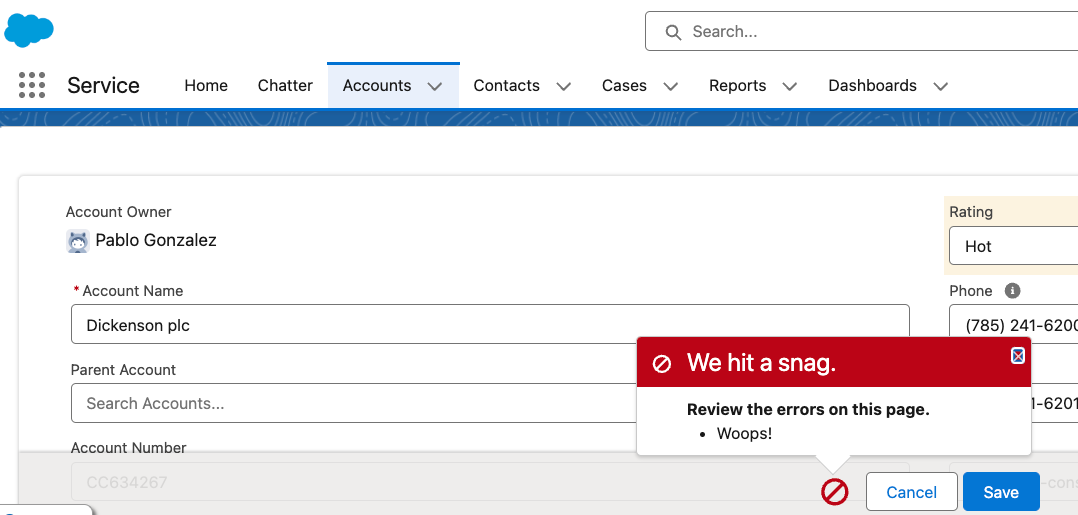
So, what’s apparent here is that how we handle exceptions depends on the run-time context of the code. If the code is the main logic being executed, letting the exception go all the way may be a good idea. But if the same code is running multiple levels deep, perhaps logging the exception is a better idea so that the parent process can continue.
We can dynamically let triggers decide what to do with exceptions by implementing a simple stack data structure to keep track of how many triggers have been called during a single transaction. Such stack could look like this
public class TriggerStack {
static private Map<String,Integer> countByTriggerName = new ...
static private List<String> orderedTriggerNames = new ...
public static void push(String triggerName){
...// add to map and list
}
public static Integer size(){
//return size of map
}
}
Then, at the beginning of each trigger, we can register the trigger in the stack. In our example, we need to register for the account, opportunity and task triggers, like this
trigger AccountTrigger on Account (...) {
TriggerStack.push('AccountTrigger');
trigger OpportunityTrigger on Opportunity (...) {
TriggerStack.push('OpportunityTrigger');
trigger TaskTrigger on Task (...) {
TriggerStack.push('TaskTrigger');
Then, in the task trigger, we can catch exceptions and decide what to do with them depending on whether this is the first trigger in the stack or whether it was called by other processes
switch on Trigger.operationType {
when AFTER_INSERT, AFTER_UPDATE {
try {
TaskTriggerHandler.afterInsert(Trigger.newMap);
} catch (Exception e) {
// let the caller know that something went wrong
// by throwing the exception again
if(**TriggerStack.size() == 1**) {
throw e;
}
// if this is not the first trigger in the stack
// log the error to prevent cascading failures
else {
System.debug(TriggerStack.toString());
Logger.error(e.getMessage());
Logger.saveLog();
}
}
}
}
Now, this may not work in all scenarios, but as with everything else in this chapter, these are thinking patterns, not recipes.
Conclusion
The core idea of this chapter is that we should understand the exception handling is not just about logging errors or recovering from them, it’s also about understanding how our code interacts with the rest of the codebase at run-time, and what appropriate action we should take given the circumstances.
Practical Takeaways
- Whenever possible, favour deep modules over using triggers in different objects to orchestrate an end-to-end process.
- If you are not sure what to do with an exception, it may be better to let it bubble up to the parent process. It’s likely that the parent process has a
try/catchblock that has more context on what to do with failures. - If you do catch an exception deep within the stack, ensure you have proper logging in place so that you don’t simply “swallow” [1] it. Swallowing an exception is worse than letting it bubble up.
- Consider using asynchronous processing to allow different business processes to run in different threads. You should do this only when absolutely necessary as working around the governor limits may add a lot of boilerplate to your code and make it harder to reason about.
- If you are not sure where to add exception handling, at a minimum start by adding it on the entry points of your application, such as Apex triggers and controllers for LWC.
[1] Swallowing an exception means catching it but doing nothing meaningful with it, such as failing to log, rethrow, or handle it properly.