A deep dive into why HappySoup.io really went down
If you use HappySoup.io for Salesforce impact analysis ("where is this used"), you probably know that between December '22 and January '23, the app was down for about 2 weeks. This outage affected approximately 1,700 users worldwide.
In this article, I explain in great detail why this happened. Be ready to learn about Heroku, Redis, the Salesforce API, and more.
What is HappySoup.io
HappySoup.io is a 100% free app for Salesforce impact analysis, also known as "where is this used?"
It provides the ability to see where custom fields, apex classes, etc., are used within your Salesforce org, allowing you to make changes with confidence because you will know in advance if something will break.
Here's an excellent explanation/demo of HappySoup:
What happened
Somewhere around January 7th or earlier, I started getting messages from users across different channels letting me know HappySoup wasn't working correctly.
Based on my estimates, this impacted around 1,700 users globally.
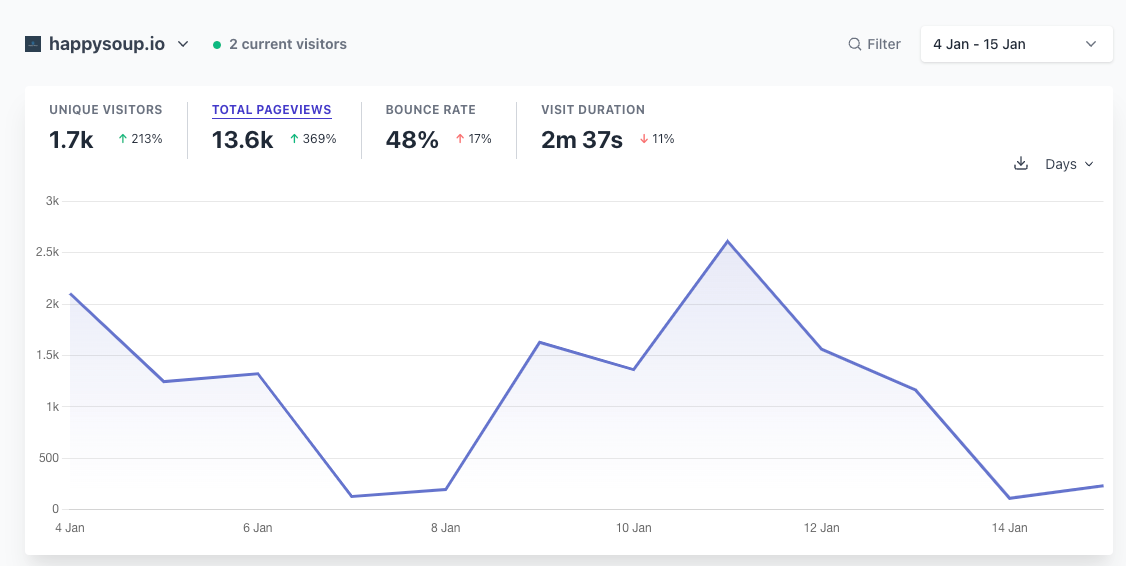
The error was also very annoying: there was no error.
Users were able to log into the app, but then when trying to query their Salesforce org metadata, they would be redirected to another page within the app. No warnings, no errors, nothing.
Just a plain old bad user experience.
What caused the issue
Long story short: The database was full, and new jobs couldn't be processed. I fixed the issue by clearing the database and changing its settings so that old data is purged when needed.
For more details, read on.
How HappySoup works
HappySoup uses the worker model suggested by Heroku:
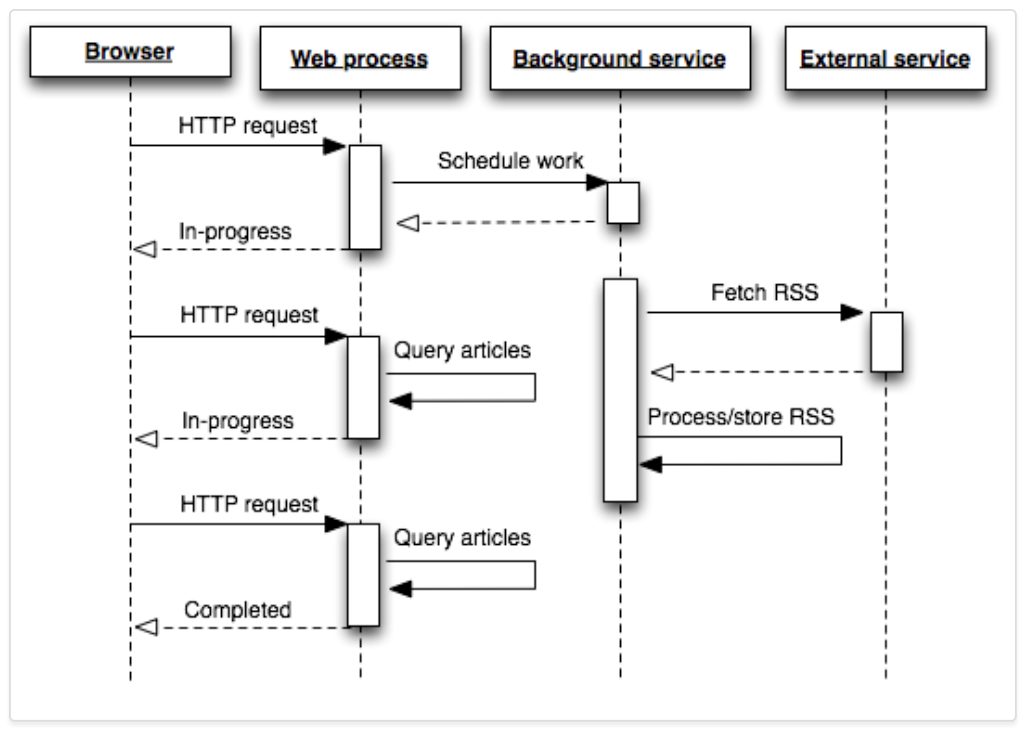
In this model, every request to the app doesn't return data immediately. Instead, it places a job in a Redis database, and the job is processed shortly after.
The client (the frontend) pings the server every few seconds checking if the job is completed. Once completed, the client is able to retrieve data from the database.
Let's see what this looks like in the code (otherwise, this article wouldn't be interesting):
Frontend submits jobs to the backend
The first step in HappySoup is to select which metadata type you want to find references for. Let's say I want to find where a custom field is used.
To do this, I first need to select Custom Field from the drop-down, which will return all the custom fields that exist in the org.
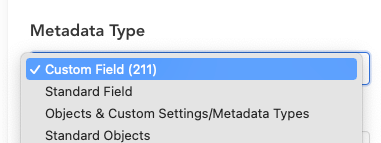
Selecting a value in the dropdown causes the following function to run on the front-end
async getMembers(){
let data = {
metadataType:this.selectedType
}
let fetchOptions = this.createPostRequest(data);
this.done = false;
this.$emit('typeSelected',this.selectedType);
this.submitJob(`/api/metadata`,fetchOptions);
}The this.submitJob function sends the job to the backend, and asks the client to check if the job is completed every 6 seconds
async function submitJob(url,fetchOptions = {}){
let res = await fetch(url,fetchOptions);
let json = await res.json();
let {jobId,error} = json;
if(jobId){
intervalId = window.setInterval(checkJobStatus,6000,jobId);
}
else if(error){
apiError.value = json;
done.value = true;
}Requests are stored in a database
Finally, in the backend, an entry is created in the database, in the form of an entry in a queue
let jobDetails = {
jobType:'LIST_METADATA',
cacheKey,
mdtype:metadataType,
sessionId:sessionValidation.getSessionKey(req)
};
let jobId = `${sessionValidation.getIdentityKey(req)}:${cacheKey}${Date.now()}`
let job = await workQueue.add(jobDetails,{jobId});
res.status(201).json({jobId:job.id});The entry in the queue simply specifies that we need to run a job to execute a listMetadata(CustomField) call to the Salesforce API to retrieve all the fields in the org. The API call is not made immediately.
The queue processes entries in the database and calls the Salesforce API
The queue will look for new entries in the database, and process them sequentially. Once this entry is picked up, we use the Salesforce Metadata API to query all the custom fields
let mdapi = metadataAPI(sessionValidation.getConnection(session),logError);
let jsonResponse = await mdapi.listMetadata(mdtype);When the API returns the data, it gets stored in same Redis job. Here's a screenshot of what the returned data looks like
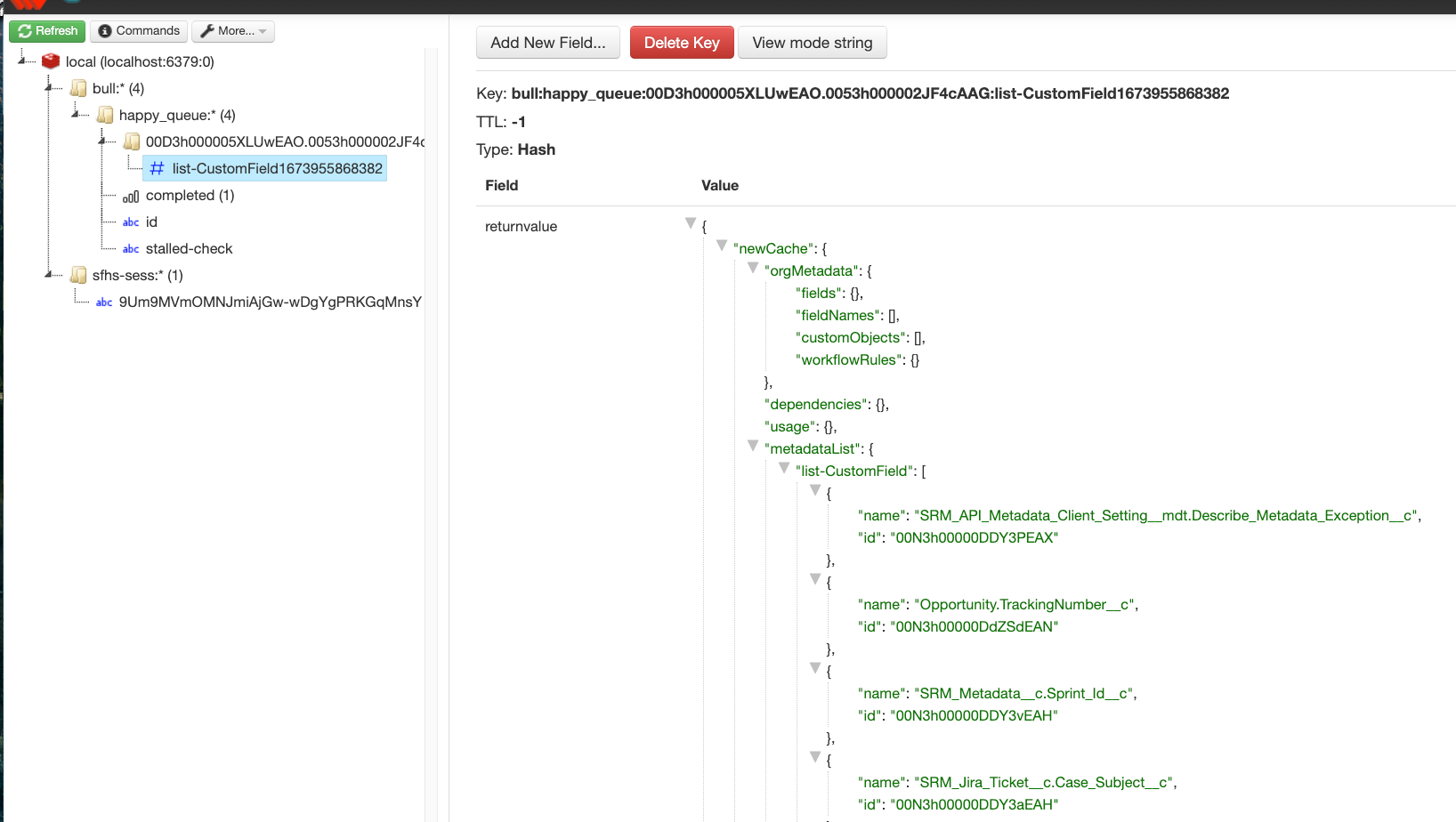
Remember the client is pinging every 6 seconds. Once it knows that the data is available, it displays it in the UI.
What really happened
These entries in the database were not deleted after the job was processed. This caused the database to become full. New entries couldn't be added, which rendered HappySoup completely useless.
Why are the entries not deleted?
Because I'm not working with Redis directly. Instead, the entries are added by Bull, a queueing system for Redis.
If I was working directly with Redis, I could specify a time-to-live (TTL) value on each entry, thus signaling to Redis that the entry can be removed after X amount of time. But again, nowhere in HappySoup do I interact with Redis; all the interactions are done through Bull.
Bull doesn't allow setting a TTL on its entries. There is a setting that allows jobs to be removed immediately after they are completed, but this doesn't work for HappySoup because the job needs to remain in the database for at least 6 seconds to allow the frontend to ping back and get the information.
I had a mechanism to delete these entries after a few minutes but turns out this mechanism wasn't working well, so some random entries remained, and slowly but surely (over months), the database became full.
How I fixed it
This fix is 2-fold:
Improved deletion mechanism
First, I changed the mechanism to delete the entries from the database after the job is completed. Now, the entry is deleted as soon as the job is complete but after we have the data in memory, which we can send back to the client.
else if(response.state == 'completed'){
let jobResult = job.returnvalue;
if(jobResult.newCache){
req.session.cache = jobResult.newCache;
}
response.response = jobResult.response;
if(process.env.DELETE_JOB_IMMEDIATELY){
deleteJobInfo(jobId);
}
res.status(200).json(response);
}In the above code, response.response has the data from the job in memory. I can then delete the job and, finally, send the data back to the client with an HTTP status of 200.
Redis Configuration
Looking at the Redis docs, there's a setting that allows me to specify what should happen when the memory is full. This is known as the max-memory policy.
For some reason, this was set to noeviction, which means Redis will throw errors when the memory is full.
Using the Heroku CLI, I changed this setting to allkeys-lru, which means that when new entries need to be added, and the memory is full, Redis will delete the least recently used key.
heroku redis:maxmemory redis-round-11563 --policy allkeys-lru
Another alternative could be to increase the Redis memory, but I'd need to pay more for that as Redis is managed by Heroku, and it's not free. In any case, that's not really a solution because I have no use case for keeping all those entries in the database.
Conclusion
So that's it. With this settings in place, I'm hoping entries will be deleted as soon as possible and that Redis should never be full again.
Building and maintaining SaaS is hard! I'm sure there are hundreds of things I could be doing better, but there's only so much time...
Thanks for reading!